Abstract
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.
Files
Bibtex
@article{garces2022surveyintrinsic,
author = {Garces, Elena and Rodriguez-Pardo, Carlos and Casas, Dan and Lopez-Moreno, Jorge},
title = {A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond},
journal = {International Journal in Computer Vision 130, 836-868},
year = {2022}
Methods and Evaluation
Inverse Appearance
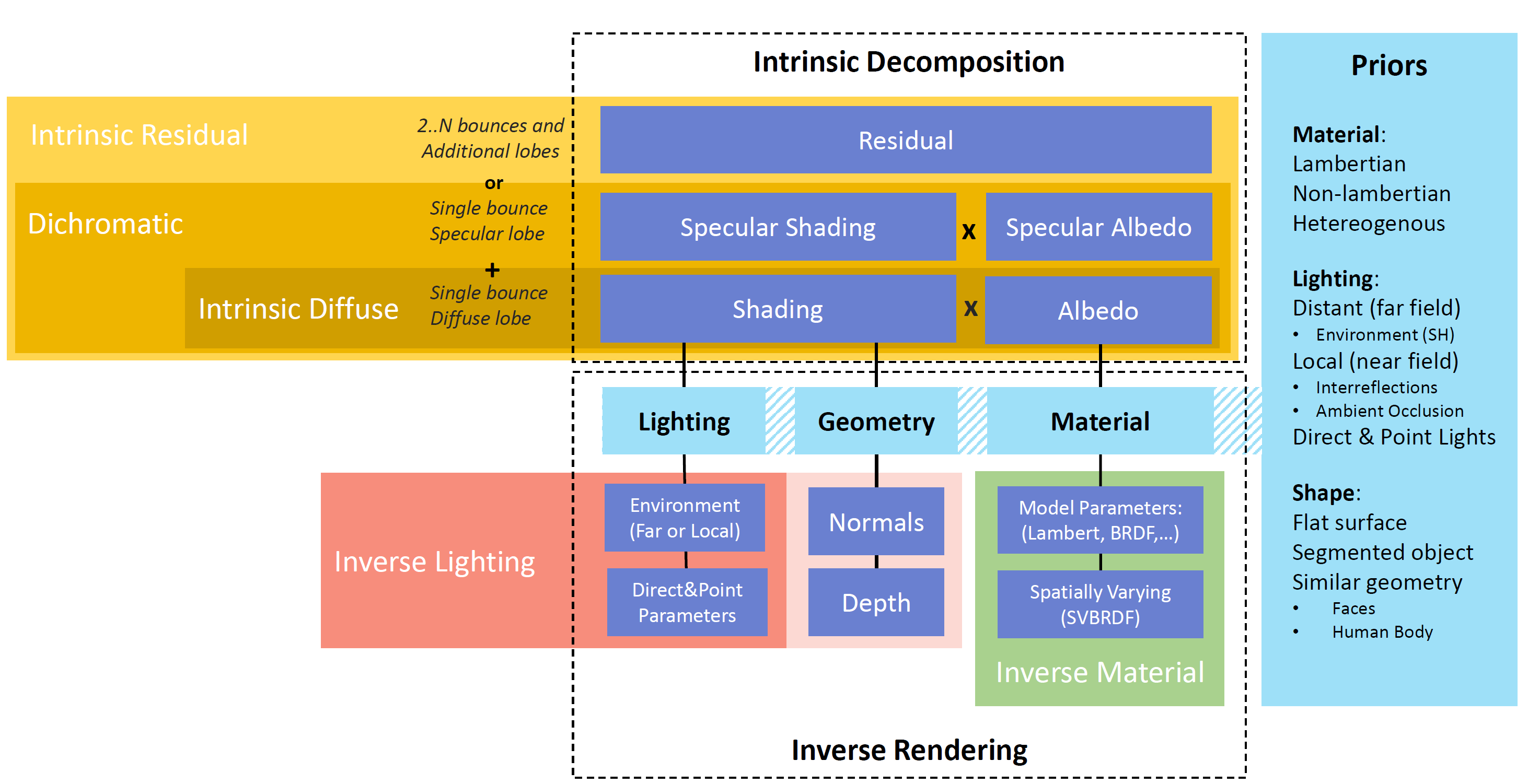
Taxonomy of single image inverse appearance reconstruction methods: intrinsic decomposition and inverse rendering.
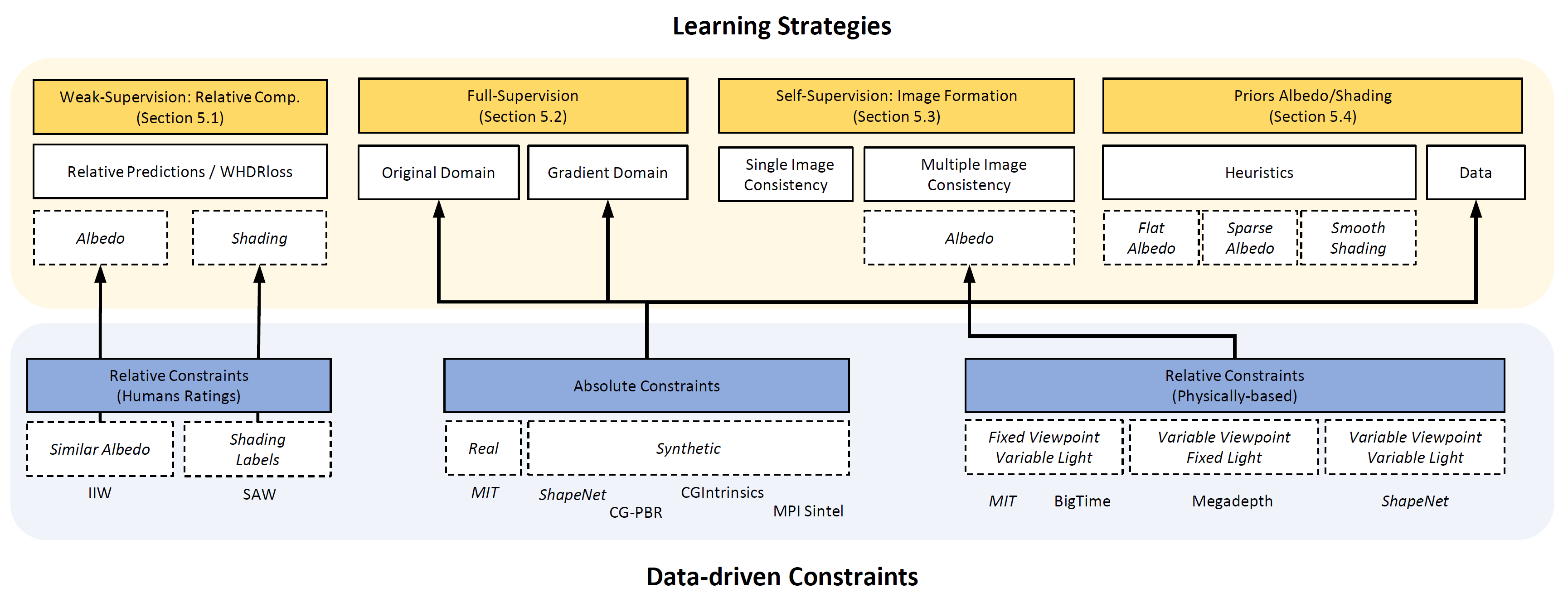
Learning Strategies
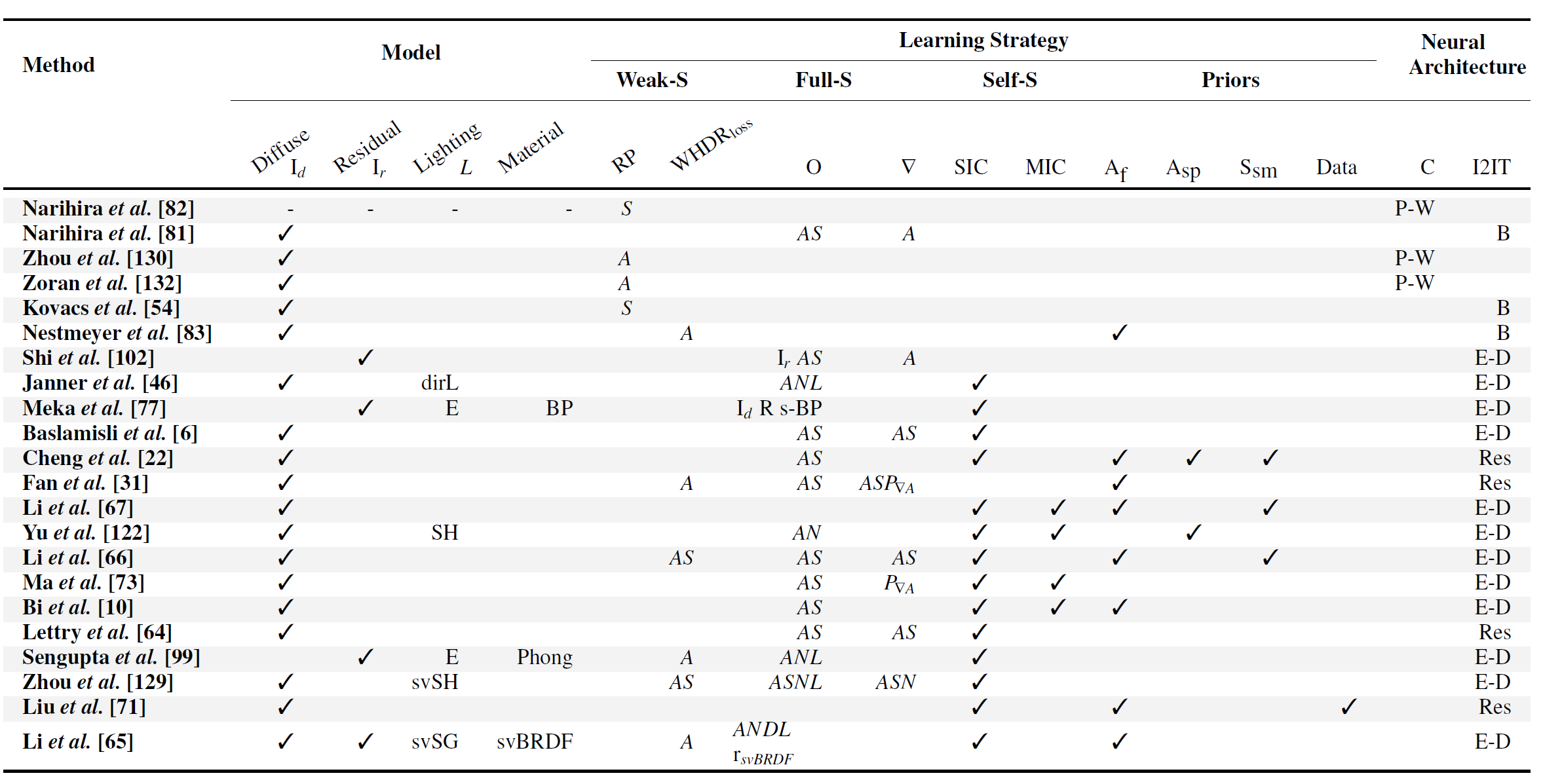
Summary of Methods
Acknowledgements
Elena Garces was partially supported by a Torres Quevedo Fellowship (PTQ2018-009868). The work was also funded in part by the Spanish Ministry of Science (RTI2018-098694-B-I00 VizLearning)